Building the Transformer from Scratch
An object-oriented implementation of the complete Transformer architecture in PyTorch — from input embeddings to the full encoder-decoder model.
Crafting the Transformer: An Object-Oriented Approach
In this section, we’re going to construct a Transformer model from the ground up. Our methodology is inspired by the insights of Umar Jamil—be sure to check out his work for a deeper understanding.
To bring the Transformer to life, we’ve broken down the development process into two primary segments: modeling and training. We’ll start with modeling, which is crucial to grasp before we proceed to the training phase. As a constant guide, we’ve placed an image of the Transformer architecture in the right corner of the page for your reference.
Within our model.py, we’ve crafted a robust framework composed of nine classes and one essential function. These components form the backbone of our implementation:
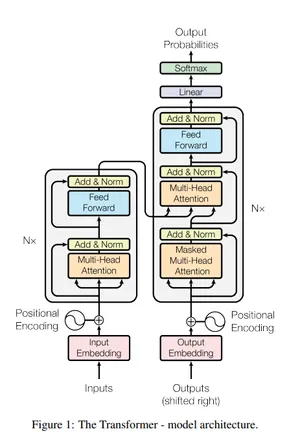
Table of Contents
- Input Embeddings
- Positional Encoding
- Layer Normalization
- Feed Forward Block
- Multi-Head Attention Block
- Residual Connection
- Encoder Block
- Encoder
- Decoder Block
- Decoder
- Projection Layer
- Transformer
- Build Transformer
The function buildTransformer weaves these components together, initializing the architecture for our model.
Understanding the Architecture In the forthcoming sections, we’ll dissect how each of these twelve classes contributes to a functioning Transformer model. It’s important to recognize the role of each component:
Classes: They represent distinct, well-defined parts of our model, encapsulating specific functionalities. Object-Oriented Design: This paradigm ensures our code is modular, making it easier to understand, maintain, and extend. By the end of this exploration, you’ll have a comprehensive understanding of the nuts and bolts of the Transformer model. Stay tuned as we delve into the intricacies of each class and function, paving the way towards a robust implementation.
Remember, the full codebase on GitHub will offer a more granular look at the inner workings of the model. This guide aims to provide a high-level understanding, ensuring you grasp the architectural decisions and algorithmic flow that define the Transformer.
Input Embeddings
class InputEmbeddings(nn.Module):
def __init__(self, d_model:int , vocab_size:int ):
super().__init__()
self.d_model = d_model
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embedding(x) * math.sqrt(self.d_model)
d_model: int - The dimensionality of the embedding space.
vocab_size: int - The size of the vocabulary of source language.
Forward Method- Accepts input x and produces embeddings scaled by the square root of d_model, leading to an output size of (vocab_size, d_model).
Notes
The embedding layer weights are scaled by the square root of
d_modelas suggested in the original paper.
Positional Encoding
The PositionalEncoding is designed to provide each token in a sequence with a unique position encoding.
Consider this example:
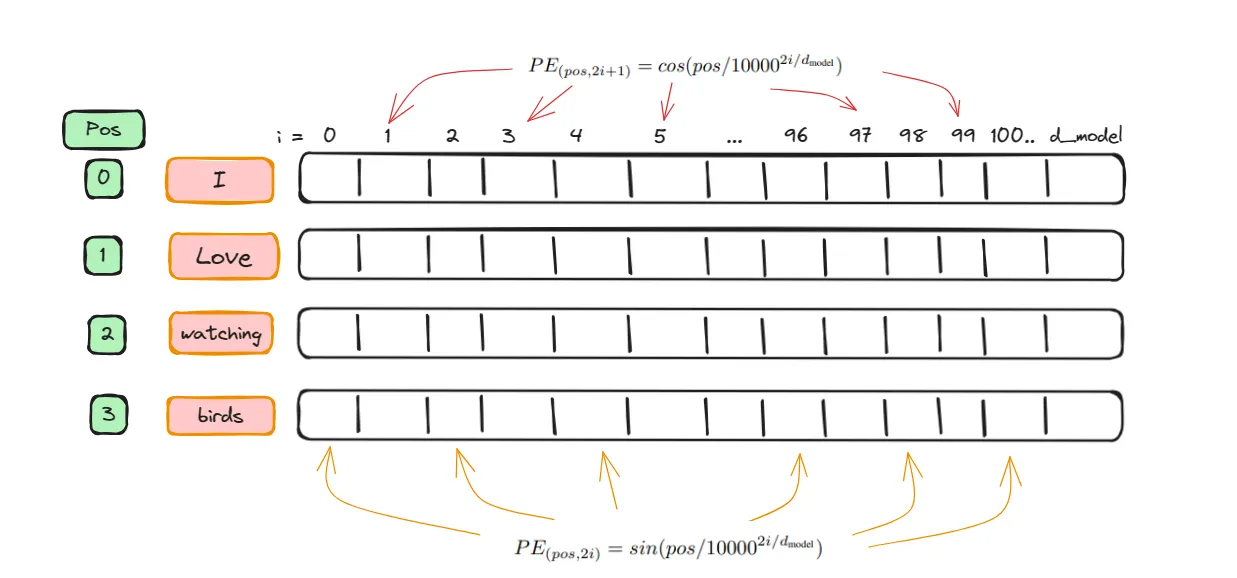
In the sentence 'I love watching birds', the word 'I' is at position 0, and the word ‘birds’ is at position 3. Each word is converted into a vector representation with a dimension of d_model(This is from embeddings layer). Positional encoding adds positional information to each vector. This is achieved by using a ‘pos’ attribute, where the even positions in the vector receive a sine function value, and the odd positions receive a cosine function value, as illustrated below
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, seq_len: int , dropout: float) ->None:
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(seq_len,d_model)
position = torch.arange(0,seq_len, dtype = torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0,d_model,2).float()*(-math.log(10000.0)/d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe',pe)
def forward(self,x):
x = x+(self.pe[:,:x.shape[1],:]).requires_grad_(False)
return self.dropout(x)
- Constructor (
__init__method)- Initializes the positional encoding with the following parameters:
d_model(int): Represents the dimensionality of the embedding space.seq_len(int): The maximum length of the sequence to be encoded.dropout(float): The dropout rate for regularization.
- Initializes the positional encoding with the following parameters:
Within the constructor:
-
A zero matrix
peof shape(seq_len, d_model)is created to store the positional encodings. -
The
positiontensor is generated with values from0toseq_len-1and reshaped byunsqueeze(1)to have a shape of(seq_len, 1). This function is used to add a dimension, making matrix operations possible. -
div_termcalculates a divisor used in the alternating sine and cosine functions based on the model’s dimension and a fixed constant (10000.0). Theexpandarangefunctions create values for this divisor. -
Sine is applied to even indices in the positional encoding matrix, while cosine is applied to odd indices. This alternation provides a unique pattern for each position.
-
The
unsqueeze(0)is used onpeto add a batch dimension, making it compatible with the expected input dimensions. -
Register Buffer
- The
register_buffermethod is used to create a persistent, non-learnable buffer for the positional encoding tensorpe. This buffer is not a parameter of the model and will not be updated during training, but it will be part of the model’s state, allowing for easy saving and loading.
- The
-
Forward Method (
forwardmethod)- In the forward pass, the input
xis added to the positional encodings, ensuring that each token’s position is considered. - The positional encodings up to
x.shape[1](the sequence length of the batch) are used, andrequires_grad_is set toFalseto indicate that no gradient should be computed. - Finally, dropout is applied to the resulting tensor.
- In the forward pass, the input
Important Points:
- The output tensor maintains the shape
(batch, seq_len, d_model), adhering to the expected input dimensions for subsequent layers. - Keeping track of tensor shapes at each operation is a crucial practice for debugging.
- The module’s design, which includes sinusoidal patterns and a non-learnable buffer, is a deliberate choice to provide the model with an effective way to interpret token positions without increasing the number of trainable parameters.
Layer Normalization
class LayerNormalization(nn.Module):
def __init__(self, eps:float = 10**-6)->None:
super().__init__()
self.eps = eps
self.alpha = nn.Parameter(torch.ones(1))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
mean = x.mean(dim = -1, keepdim=True)
std = x.std(dim = -1, keepdim=True)
return self.alpha * (x-mean)/(std +self.eps)+self.bias
The LayerNormalization module stabilizes the activation distribution throughout the training process.
self.alphais a learnable scaling parameter, initialized to one.self.biasis a learnable shifting parameter, initialized to zero.- The forward pass computes the mean and standard deviation across the last dimension of the input
x, normalizes it, then applies the learned scale and shift. - The epsilon value
epsadds stability to the normalization process.
Feed Forward Block
class FeedForwardBlock(nn.Module):
def __init__(self, d_model: int, d_ff:int, dropout:float) -> None:
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))
The FeedForwardBlock is used in both encoder and decoder. It consists of two linear transformations with a ReLU activation in between.
d_model: Input and output feature dimension.d_ff: Hidden layer dimension, typically larger thand_model.- Dropout is applied after the activation function to reduce overfitting.
Multi-Head Attention Block
class MultiHeadAttentionBlock(nn.Module):
def __init__(self,d_model: int,h:int, dropout:float) ->None:
super().__init__()
self.d_model =d_model
self.h = h
assert d_model % h == 0, "d_model is not divisible by h"
self.d_k = d_model//h
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
@staticmethod
def attention(query, key, value, mask, dropout: nn.Dropout):
d_k = query.shape[-1]
# (batch, h, seq_len, d_k) --> (batch, h, seq_len, seq_len)
attention_scores = (query @ key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
attention_scores.masked_fill_(mask == 0, -1e9)
attention_scores = attention_scores.softmax(dim=-1)
if dropout is not None:
attention_scores = dropout(attention_scores)
return (attention_scores @ value), attention_scores
def forward(self, q, k, v, mask):
query = self.w_q(q)
key = self.w_k(k)
value = self.w_v(v)
query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1,2)
key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1,2)
value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1,2)
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, mask, self.dropout)
x = x.transpose(1,2).contiguous().view(x.shape[0],-1,self.h * self.d_k)
return self.w_o(x)
The MultiHeadAttentionBlock is the crux of the attention mechanism:
- The
attentionfunction is astaticmethod, allowing it to be used across encoder and decoder without a class instance. - Queries, keys, and values are reshaped into 4D tensors to facilitate multi-head processing.
- The model concurrently processes inputs through multiple attention ‘heads’, focusing on different aspects of the input sequence.
- Multi-head attention is used three times in the transformer — twice in the decoder and once in the encoder.
Residual Connection
class ResidualConnection(nn.Module):
def __init__(self, dropout: float)->None:
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization()
def forward(self, x, sublayer):
return x +self.dropout(sublayer(self.norm(x)))
The residual connection (x + ...) allows gradients to flow directly through the network without being hindered by deep layers. Layer normalization is applied before the sublayer, and dropout regularizes the output.
Encoder Block
class EncoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout:float):
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connection = nn.ModuleList([ResidualConnection(dropout) for _ in range(2)])
def forward(self, x, src_mask):
x = self.residual_connection[0](x, lambda x:self.self_attention_block(x,x,x, src_mask))
x = self.residual_connection[1](x, self.feed_forward_block)
return x
Each encoder block applies self-attention followed by a feed-forward network, with residual connections around both.
Encoder
class Encoder(nn.Module):
def __init__(self, layers: nn.ModuleList) -> None:
super().__init__()
self.layers = layers
self.norm = LayerNormalization()
def forward(self,x, mask):
for layer in self.layers:
x = layer(x,mask)
return self.norm(x)
The encoder iteratively processes input through each encoder block, with a final layer normalization.
Decoder Block
class DecoderBlock(nn.Module):
def __init__(self, self_attention_block:MultiHeadAttentionBlock, cross_attention_Block: MultiHeadAttentionBlock,
feed_forward_block:FeedForwardBlock, dropout: float):
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_Block = cross_attention_Block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(3)])
def forward(self, x, encoder_output, src_mask, tgt_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x,x,x,tgt_mask))
x = self.residual_connections[1](x, lambda x: self.self_attention_block(x,encoder_output,encoder_output,src_mask))
x = self.residual_connections[2](x, self.feed_forward_block)
return x
The decoder block integrates three operations: self-attention (masked), cross-attention with encoder output, and feed-forward processing. Three residual connections wrap each component.
Decoder
class Decoder(nn.Module):
def __init__(self, layers: nn.ModuleList) -> None:
super().__init__()
self.layers = layers
self.norm = LayerNormalization()
def forward(self, x, encoder_output, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.norm(x)
The target mask (tgt_mask) prevents the decoder from seeing future tokens — essential for autoregressive generation.
Projection Layer
class ProjectionLayer(nn.ModuleList):
def __init__(self, d_model:int, vocal_size:int ) -> None:
super().__init__()
self.proj = nn.Linear(d_model, vocal_size)
def forward(self, x):
return torch.log_softmax(self.proj(x),dim=-1)
Maps the decoder output from d_model dimensions to vocabulary size, applying log softmax for numerical stability.
Transformer
class Transformer(nn.Module):
def __init__(self, encoder:Encoder, decoder: Decoder, src_embed: InputEmbeddings,
tgt_embed: InputEmbeddings, src_pos: PositionalEncoding, tgt_pos: PositionalEncoding,
Projection_Layer: ProjectionLayer)-> None:
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_emded = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = Projection_Layer
def encode(self, src, src_mask):
src = self.src_emded(src)
src = self.src_pos(src)
return self.encoder(src, src_mask)
def decode(self, encoder_output, src_mask, tgt, tgt_mask):
tgt = self.tgt_embed(tgt)
tgt = self.tgt_pos(tgt)
return self.decoder(tgt, encoder_output, src_mask, tgt_mask)
def project(self, x):
return self.projection_layer(x)
The Transformer class ties everything together: encode the source, decode the target using encoder output, then project to vocabulary space.
Build Transformer
def build_transformer(src_vocab_size: int, tgt_vocab_size: int,
src_seq_len: int, tgt_seq_len: int, d_model:int = 512,
N: int = 6 , h: int = 8, dropout: float = 0.1, d_ff: int = 2048 )->Transformer:
src_embed = InputEmbeddings(d_model, src_vocab_size)
tgt_embed = InputEmbeddings(d_model, tgt_vocab_size)
src_pos = PositionalEncoding(d_model, src_seq_len, dropout)
tgt_pos = PositionalEncoding(d_model, tgt_seq_len, dropout)
encoder_blocks = []
for _ in range(6):
encoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout)
encoder_block = EncoderBlock(encoder_self_attention_block, feed_forward_block, dropout)
encoder_blocks.append(encoder_block)
decorder_blocks = []
for _ in range(N):
decoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
decorder_cross_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout)
decoder_block = DecoderBlock(decoder_self_attention_block, decorder_cross_attention_block, feed_forward_block, dropout)
decorder_blocks.append(decoder_block)
encoder = Encoder(nn.ModuleList(encoder_blocks))
decorder = Decoder(nn.ModuleList(decorder_blocks))
projection_layer = ProjectionLayer(d_model, tgt_vocab_size)
transformer = Transformer(encoder, decorder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer)
for p in transformer.parameters():
if p.dim() >1:
nn.init.xavier_uniform_(p)
return transformer
The factory function assembles all components and initializes parameters with Xavier uniform initialization — a common practice for preventing vanishing/exploding gradients in deep networks like the Transformer.